Il y a un peu plus d’un mois, j’ai décidé d’automatiser une opération que je pensais assez simple :
Réaliser un automate pour récupérer un fichier sur internet et l’envoyer à quelques destinataires
Je ne pensais pas en faire un article, mais tous les efforts consentis et les recherches associées le valent bien 😉 Ce sera aussi un aide mémoire pour pas mal de manipulations que je ne réalise pas fréquement.
Challenge 1 : Je ne connais pas l’heure à laquelle le fichier à récupérer est disponible. Ce fichier est le journal Sud-Ouest Edition Dordogne (ce qui explique l’image de cet article) en format .pdf qui est mis à disposition en cours de nuit mais parfois c’est en début de matinée s’il y a du retard.
Solution 1 : Je lance mon shell via la crontab périodiquement avec le format suivant :
|
1 |
*/30 5-7 * * * /home/pi/domoticz/scripts/divers/selenium_sud_ouest.sh |
Ce qui couvre la plage 5h00-7h30, si on dépasse parfois 7h30, je modifierai la plage horaire.
Solution 1 bis : La solution 1 n’était pas satisfaisante car lorsque le fichier était disponible tardivement, il fallait plusieurs connexions avant d’obtenir un résultat. Ceci n’était pas très « discret » et montrait à Sud-Ouest la présence d’un robot (avec une IP fixe en plus !) qui intervient régulièrement. J’ai donc dû modifier ma logique de traitement pour ne démarrer le processus que lorsque le journal est disponible. Un mail est envoyé aux abonnés chaque nuit dès que le journal est prêt, je vais utiliser ce mail comme déclencheur en passant par les étapes suivantes :
- Renvoi automatique d’une copie du mail de Sud-Ouest vers une boîte mail hébergée sur la machine où se déroule le processus. J’utilise un filtre dans Gmail pour faire cette opération.
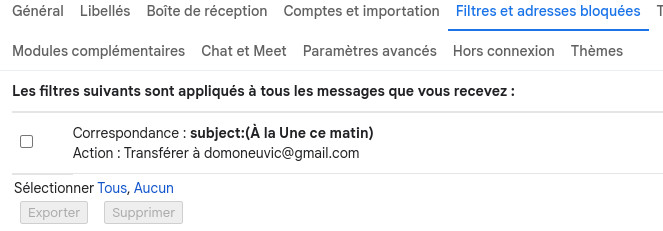
- Sur la boîte de réception du mail transféré, passage de ce mail dans la catégorie « Important« . J’utilise un filtre dans Thunderbird réaliser cette opération.
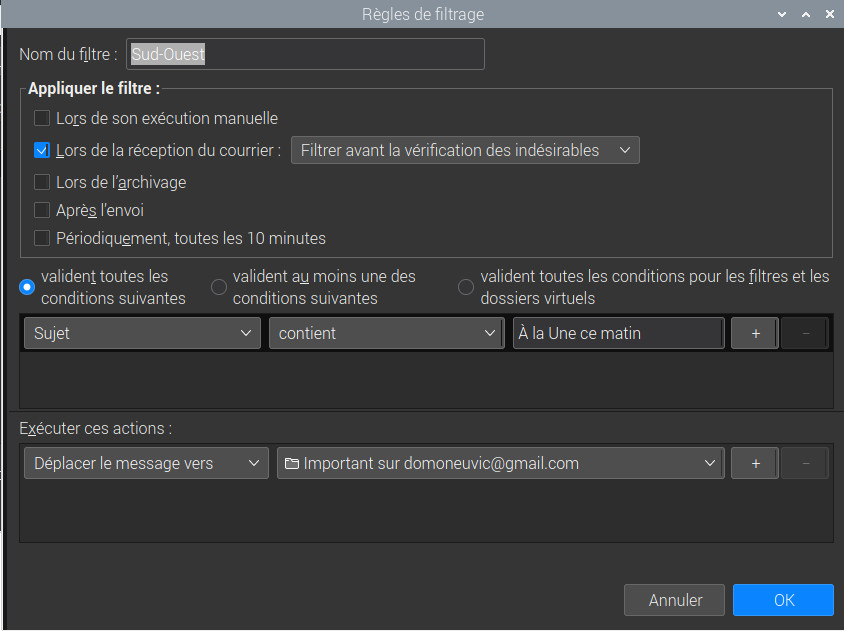
- Je vérifie ensuite, au début du shell de traitement quotidien, si la date de mise à jour du fichier qui contient les mails importants a changé depuis une heure. Si la date n’a pas changé le shell est terminé, ainsi le scénario de téléchargement ne se déroule qu’une seule fois chaque nuit moins d’une heure après la mise à disposition du journal. Pour cette dernière opération, c’est la commande find que j’utilise.
|
1 2 3 |
if [[ -n $(find -mindepth 1 -type f -iname $fich_mailso -mmin -60) ]] then echo '# Fichier Important.msf modifié le journal du jour est disponible' |
Challenge 2 : Le nom du fichier intégre la date du jour en format AAAA-MM-JJ.
Solution 2 : J’utilise la commande date pour obtenir le format souhaité et aussi pour formatter la date en français JJ-MM-AAAA. J’obtiens 2 variables $date et $datef.
|
1 2 3 4 5 |
# Variables utilisées pour construire le nom du fichier à récupérer date=$(date '+%Y-%m-%d') # echo '# Début du nom de fichier $date : '$date datef=$(date '+%d-%m-%Y') # echo '# Date du jour en format français pour la semaine $datef : '$datef |
Challenge 3 : Le reste du nom du fichier change aussi en fonction du jour de la semaine (semaine ou dimanche) car la semaine c’est l’édition Dordogne et le dimanche l’édition Dordogne-Lot et Garonne .
Solution 3 : Je construis 2 noms différents, mais je ne sais pas quelle est la règle pour les jours fériés, on verra au fur et à mesure. Comme vous pouvez le constater, il y a systématiquement des affichages des variables utilisées pour contrôler les formats pendant la mise au point. Ils sont ensuite transformés en commentaires (mais conservés pour un usage futur !) pour ne pas alourdir les affichages lors de l’exécution du script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# Variable utilisée pour construire le chemin du fichier à récupérer deb_chemin='/home/pi/Téléchargements/' # echo '# Début du chemin $deb_chemin : '$deb_chemin # Pour un jour de semaine : Edition Dordogne _8ABC.pdf fin_fichier_sem='_8ABC.pdf' # echo '# Fin du nom de fichier $fin_fichier_sem : '$fin_fichier_sem nomfichier_sem=$date$fin_fichier_sem # echo '# Nom du fichier $nomfichier_sem : '$nomfichier_sem fichier_sem=$deb_chemin$nomfichier_sem # echo '# Chemin complet $fichier_sem : '$fichier_sem # Pour un dimanche : Edition Dordogne et Lot et Garonne _CEN.pdf fin_fichier_dim='_CEN.pdf' # echo '# Fin du nom de fichier $fin_fichier_dim : '$fin_fichier_dim nomfichier_dim=$date$fin_fichier_dim # echo '# Nom du fichier $nomfichier_dim : '$nomfichier_dim fichier_dim=$deb_chemin$nomfichier_dim # echo '# Chemin complet $fichier_dim : '$fichier_dim # Valorisation du nom de fichier à traiter en fonction des résultats du téléchargement if [ -f $fichier_sem ] then fichier=$fichier_sem echo -e '# Le fichier '$fichier' existe ;-) ' elif [ -f $fichier_dim ] then fichier=$fichier_dim echo -e '# Le fichier '$fichier' existe ;-) ' else fichier="absent" echo -e "# Attention le fichier journal du "$datef" n'est pas présent dans le répertoire de Téléchargements :-( " fi |
Après la phase de téléchargement, en fonction du fichier reçu, je connais le nom exact du fichier du jour.
Challenge 4 : Le shell s’exécute plusieurs fois par jour et que je ne veux/doit récupérer le fichier qu’une seule fois. Il y a un contrôle sur le site de Sud-Ouest du nombre de téléchargements et de plus si je télécharge plusieurs fois, le nom du fichier change à chaque fois (ajout de (n) en fin de fichier).
Solution 4 : Je vérifie en début de shell si le fichier du jour est présent. Si c’est le cas, le shell s’arrête, sauf si les mails n’ont pas été envoyés.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Vérification de la présence du fichier Sud-Ouest du jour dans le répertoire de téléchargement # si le fichier est absent on lance la récupération via le scénario Selenium # le nom du fichier est différent entre un jour de semaine et un dimanche if ([ ! -f $fichier_sem ] && [ ! -f $fichier_dim ]) || [ ! -f $fichier_mok ] then # un fichier est absent => lancement de la récupération if [ -f $fichier_sem ] then fichier=$fichier_sem echo -e '# Le fichier '$fichier' est déjà présent ' elif [ -f $fichier_dim ] then fichier=$fichier_dim echo -e '# Le fichier '$fichier' est déjà présent ' else fichier="absent" echo -e "# Le fichier journal du "$datef" n'est pas présent => lancement de la récupération " |
Challenge 5 : Je ne dois envoyer le fichier qu’une seul fois à chaque destinataire.
Solution 5 : Après la phase d’envoi des mails, je crée un fichier spécifique indiquant que les mails sont envoyés. Ce fichier ($fichier_mok) contient la date du jour. Si le fichier existe, je n’envoie pas les mails, c’est déjà fait.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# Variables utilisées pour indiquer si l'envoi des mails est bien fait envmail='mailenvoi' fichier_mok=$deb_chemin$envmail$date'.ok' # echo '# Fichier mail envoi $fichier_mok : '$fichier_mok # Si le fichier du journal est présent => vérification de l'envoi des mails # Vérification de la présence du fichier témoin indiquant l'envoi des mails dans le répertoire de téléchargement # si le fichier témoin est absent on envoie les mails vers les destinataires # car l'envoi n'a pas encore été réalisé if [ ! -f $fichier_mok ] then # le fichier témoin est absent echo -e "# Le fichier témoin d'envoi de mail "$fichier_mok" n'existe pas dans le répertoire de téléchargement ! " # Création du fichier témoin pour indiquer si l'envoi des mails est bien fait touch $fichier_mok echo -e '# Le fichier '$fichier_mok" vient d'être créé " |
Ce fichier est aussi utilisé en début de Shell : si le fichier est présent, c’est que le traitement du jour est terminé (voir le test [ ! -f $fichier_mok ] dans Solution 4).
Challenge 6 : Envoyer un mail aux destinataires.
Solution 6 : J’utilise la commande mutt dans laquelle après -s on met le sujet du mail, et le corps du mail précéde dans une commande echo. Le destinataire est indiqué en fin de ligne après 2 tirets ‘—‘.
|
1 |
echo -e "Voici le lien vers le journal du jour (edition Dordogne) appuyer sur le lien ci-dessous pour ouvrir le journal :\r\n\r\n"$lien | mutt -s "[Sud-Ouest] Lien vers le journal du $datef " -- ${mail[$i]} |
-e dans la commande echo indique que l’on va utiliser des caractères spéciaux. Dans notre cas, \r et \n pour fin de ligne et nouvelle ligne.
Challenge 7 : Le fichier doit être envoyé soit en pièce jointe du mail, soit dans un lien intégré au corps du mail car certaines personnes ne peuvent pas utiliser les liens.
Solution 7 : La commande indiquée dans la solution 6 est celle qui fonctionne pour le lien intégré dans le corps du mail ($lien). Ci-dessous la commande pour ajouter un fichier joint.
|
1 2 |
echo -e 'Voici le journal du jour - Edition Dordogne ' | mutt -s "[Sud-Ouest] Le journal du $datef " -a $fichier -- ${mailpdf[$j]} echo -e "# Mail pour le journal "$fichier" envoyé vers "${mailpdf[$j]}" " |
Dans la commande mutt, on ajoute -a puis le nom du fichier à joindre au mail.
Challenge 8 : Différencier les personnes devant recevoir un lien de celles qui utilisent un fichier joint.
Solution 8 : J’utilise 2 tableaux différents, un pour les liens et un pour les fichiers joints. Dans 2 boucles for je traite les tableaux, un indexé par i et un indexé par j.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# Variables utilisées pour l'envoi des mails avec liens (stockées sous forme de tableau) mail[1]=xx.yy@gmail.com mail[2]=xx.yyy@gmail.com mail[3]=xx.yy@gmail.com mail[4]=xx.yy@orange.fr mail[5]=xy.xy@gmail.com # Variables utilisées pour l'envoi des mails avec fichier .pdf (stockées sous forme de tableau) mailpdf[1]=zzz@gmail.com mailpdf[2]=zzzz@gmail.com mailpdf[3]=zzzzz@gmail.com # envoi des mails avec le fichier du jour en pièce jointe ou avec un lien vers Google Drive # echo '# Fichier $fichier : '$fichier for (( i=1; i<6; i++ )) do echo -e "Voici le lien vers le journal du jour (edition Dordogne) appuyer sur le lien ci-dessous pour ouvrir le journal :\r\n\r\n"$lien | mutt -s "[Sud-Ouest] Lien vers le journal du $datef " -- ${mail[$i]} echo -e "# Mail pour le journal "$fichier" envoyé vers "${mail[$i]}" " done for (( j=1; j<4; j++ )) do echo -e 'Voici le journal du jour - Edition Dordogne ' | mutt -s "[Sud-Ouest] Le journal du $datef " -a $fichier -- ${mailpdf[$j]} echo -e "# Mail pour le journal "$fichier" envoyé vers "${mailpdf[$j]}" " done |
Challenge 9 : Gérer les fichiers pour lesquels il faut transmettre un lien.
Solution 9 : J’utilise Google Drive qui me permet d’avoir de l’espace de stockage et un lien permanent vers le répertoire contenant les journaux. D’abord, il faut copier le journal du jour vers un répertoire dédié à Google Drive (sinon la synchronisation ajouterait tous les fichiers du répertoire de téléchargement et pas seulement les journaux), c’est un simple cp qui fait ça. Pour le transfert vers Google Drive, c’est la commande rclone qui fait le job (je ne détaille pas la syntaxe 🙄 ).
|
1 2 3 4 5 6 7 8 9 10 |
# Ajout de la copie du fichier vers le répertoire dédié pour Google Drive echo -e "# Fichier journal à copier : "$fichier" " echo -e "# Répertoire à utiliser pour la copie : "$drive_chemin" " cp $fichier $drive_chemin echo -e "# Le fichier "$fichier" est copié vers "$drive_chemin" " # transfert du pdf récupéré vers Google Drive # la configuration spécifique de rclone se trouve dans le fichier rclone.conf avec le token d'accès à Google Drive # emplacement du fichier de configuration : /home/pi/.config/rclone/rclone.conf /usr/bin/rclone copy --update --verbose --transfers 30 --checkers 8 --contimeout 60s --timeout 300s --retries 3 --low-level-retries 10 --stats 1s $drive_chemin $drive_google |
Challenge 10 : Gérer le cas des fichiers vides car parfois le téléchargement se fait, le fichier existe bien mais il est vide (la poisse !).
Solution 10 : Ajout d’un test pour vérifier que le fichier n’est pas vide (avec -s) et suppression de ce fichier vide sinon on ne récupérera pas le fichier correct car on va considérer que le fichier est bien présent donc pas de nouveau téléchargement !
|
1 2 3 4 5 6 |
# Vérification pour contrôler que le fichier n'est pas vide if [ ! -s $fichier ] then sudo rm $fichier echo -e '# Le fichier '$fichier' est vide => il est supprimé ' fi |
Challenge 11 : Récupérer le journal du jour sur le site de Sud-Ouest.
Solution 11 : Aïe ! C’est le challenge le plus délicat. J’ai pas mal galéré avant d’avoir un résultat satisfaisant. J’utilise un logiciel de test d’interface web qui simule des actions dans un navigateur. C’est Selenium, j’en ai testé d’autres sans résultat (Katalon par exemple).
Le logiciel doit fonctionner en ligne de commande pour être intégré dans un shell qui va s’exécuter automatiquement. Cette fonction existe bien dans Selenium, c’est selenium-side-runner mais je n’ai pas réussi à la faire fonctionner dans mon contexte. J’ai donc intégré le scénario de test dans un programme Python (c’est aussi une option de Selenium) et ça marche (pour l’instant !).
J’ai du utiliser Firefox (que je n’utilise pas habituellement et qui est dédié à Selenium dans mon cas) pour ne pas mélanger avec Chrome qui est mon navigateur usuel. Cette séparation me permet d’avoir un paramètrage spécifique (répertoire de téléchargement, gestion des cookies, etc.).
Je précise que tout cela fonctionne sur le Raspberry que j’utilise pour la bureautique.
Le principe : à partir d’une extension Selenium ajoutée à Firefox, on enregistre les actions faites dans le navigateur. On peut ensuite rejouer le scénario enregistré pour vérifier qu’il est correct. Il existe des options d’exportation du scénario. J’ai choisi de l’exporter en Python et j’ai adapté un programme Python qui s’exécute dans mon shell.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.firefox.options import Options as FirefoxOptions options = FirefoxOptions() options.add_argument("--headless") driver = webdriver.Firefox(options=options) print ("Fin options Firefox") driver.get("https://kiosque.sudouest.fr/") driver.set_window_size(1700, 1000) driver.find_element(By.CSS_SELECTOR, "#didomi-notice-agree-button > span").click() driver.find_element(By.CSS_SELECTOR, ".icon-account").click() print ("Fin Acceptation cookies Sud-Ouest") driver.find_element(By.ID, "loginForm_username").click() driver.find_element(By.ID, "loginForm_username").send_keys("xx.yy@gmail.com") print ("Fin saisie username") driver.find_element(By.ID, "loginForm_password").click() driver.find_element(By.ID, "loginForm_password").send_keys("pwd") print ("Fin saisie password") driver.find_element(By.CSS_SELECTOR, ".btn").click() print ("Fin Connexion") driver.find_element(By.CSS_SELECTOR, ".text-underline").click() print ("Fin Téléchargement") driver.close() print ("Fin et close") |
C’est un programme de 17 lignes (sans les « print ») qui fait les choses suivantes :
- lignes 1 à 7 : définition du contexte avec en particulier la ligne 5 qui indique que l’on va utiliser le navigateur Firefox sans écran puisqu’on est en ligne de commande sans interface graphique.
- ligne 8 : on indique l’url du site où l’on souhaite se rendre.
- ligne 9 : on définit la taille de l’écran (virtuel bien entendu) mais c’est très important car cela permet d’éviter des chevauchements de fenêtres qui perturbent le déroulement du scénario.
- lignes 10 à 12 : le site envoie une fenêtre demandant l’acceptation des cookies, on clique sur Accepter et fermer
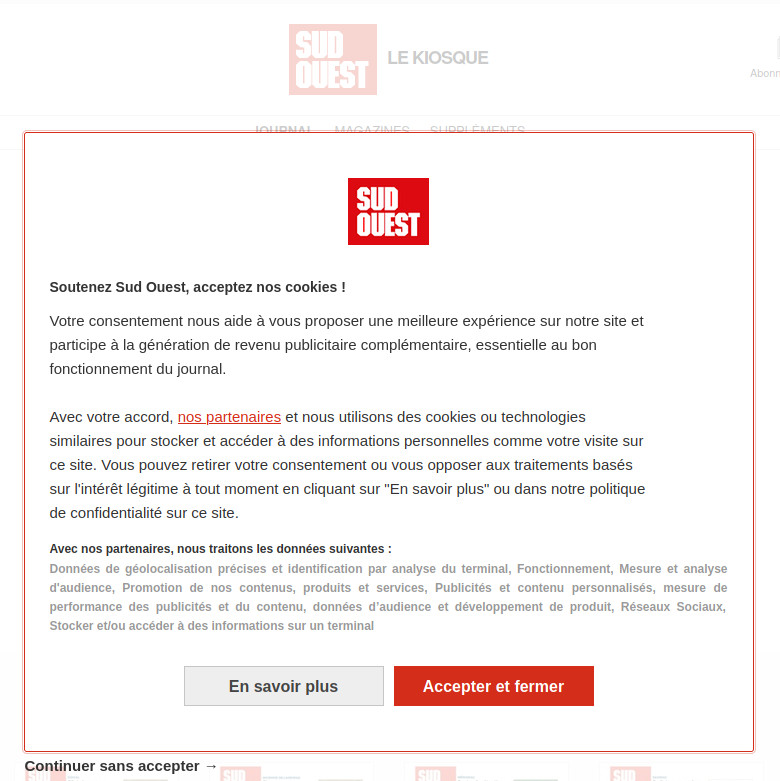
- lignes 13 à 20 : on clique sur Connexion et on rentre user/mot de passe + Se Connecter


- ligne 21 : on clique sur Télécharger après l’affichage du journal du jour par le site
Cela semble assez simple mais la mise au point est longue et chaque changement dans l’interface du site va perturber le déroulement du scénario.
Challenge 12 : Eviter la saturation des répertoires de téléchargement, de synchronisation avec Google Drive et de Google Drive lui-même.
Solution 12 : Suppression automatique d’un fichier s’il est présent depuis plus de 7 jours en calculant le nom du fichier et en faisant un rm de celui-ci.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Variables utilisées pour définir le nom des fichiers à supprimer - Ajouter le cas des débuts de mois !!! js=$(date '+%d') # echo '# Jour $js : '$js js=$(($js - 7)) # echo '# Jour du fichier à supprimer $js : '$js dates=$(date '+%Y-%m-')$js # echo '# Date du jour du fichier à supprimer $dates : '$dates # Valorisation du nom de fichier à traiter en fonction des résultats du téléchargement # et définition du fichier à supprimer if [ -f $fichier_sem ] then fichier=$fichier_sem echo -e '# Le fichier '$fichier' existe ;-) ' fics=$drive_chemin$dates$fin_fichier_sem echo '# Nom du fichier à supprimer pour un jour de semaine $fics : '$fics elif [ -f $fichier_dim ] then fichier=$fichier_dim echo -e '# Le fichier '$fichier' existe ;-) ' fics=$drive_chemin$dates$fin_fichier_dim echo '# Nom du fichier à supprimer pour un dimanche $fics : '$fics # suppression du fichier de la semaine précédente sudo rm $fics |
Pour Google Drive, il faut modifier la commande utilisée dans rclone en remplacant le mode copy par le mode sync qui permet la suppression automatique dans Google Drive des fichiers qui ne sont pas présents dans le répertoire à synchroniser.
Au final, énormément de temps passé sur ce TP mais la satisfaction d’avoir réussi à contourner tous les obstacles et d’avoir beaucoup appris 😆 .
Le shell associé aux commandes en ligne : Une Sacrée Puissance !